Цена распределенности
Прежде, чем описывать детали своего подхода к разделению, мы представим серию экспериментов, которые мы выполнили для измерения стоимости распределенных транзакций. Эти результаты показывают, что распределенные транзакции являются дорогостоящими, и что нахождение правильного разделения критически важно для достижения хорошей производительности распределенной системы баз данных OLTP.
В распределенной системе баз данных без общих ресурсов транзакции, обращающиеся к данным только одного узла, выполняются без дополнительных накладных расходов. Операторы этой транзакции обрабатываются над одной базой данных, а в завершение выполняются команды фиксации (commit) или аварийного завершения (abort). Однако если операторы распределяются по нескольким узлам, то для обеспечения атомарности и сериализуемости транзакций требуется использование двухфазной фиксации (two-phase commit) или какого-либо аналогичного распределенного протокола согласования. Это приводит к появлению дополнительных сетевых сообщений, снижению пропускной способности, увеличению задержки и потенциальному появлению распределенных тупиковых ситуаций. Поэтому мы хотим избегать распределенных транзакций.
Для количественной оценки влияния распределенных транзакций мы выполнили простой эксперимент с использованием MySQL. Мы создали таблицу simplecount с двумя столбцами целого типа: id и counter. Клиенты в одной транзакции читают две строки, выдавая два запроса вида SELECT * FROM simplecount WHERE id = ?. Каждый запрос возвращает одну строку. Мы исследовали производительность двух стратегий: (i) каждая транзакция выполняется на одном сервере и (ii) каждая транзакция распределяется между несколькими машинами с использованием поддерживаемой MySQL двухфазной фиксации (XA-транзакции) и нашего собственного координатора распределенных транзакций.
Каждый клиент выбирал строки случайным образом в соответствии с одной из этих стратегий и после получения ответа немедленно посылал следующий запрос. Мы тестировали эту рабочую нагрузку на вычислительном комплексе, включавшем до пяти серверов.
См. подробное описание нашей экспериментальной конфигурации в Приложении A. Мы использовали 150 одновременно функционирующих клиентов, чего было достаточно для насыщения процессоров всех пяти серверов. Таблица simplecount содержала 150000 строк (по тысяче на каждого клиента), так что база данных полностью помещалась в буферных пулах наших серверов (128 мегабайт). Это имитировало рабочую нагрузку над базой данных, располагаемой в основной памяти, что не является редкой ситуацией для OLTP.
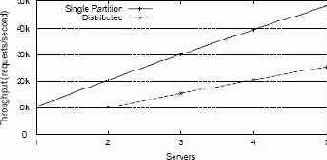
Рис. 1. Пропускная способность распределенных транзакций.
В идеальном мире локальные и распределенные транзакции в этом тесте достигали бы схожей производительности, поскольку они обращаются к одному и тому же числу записей с использованием одного и того же числа операторов. Однако результаты эксперимента, показанные на рис. 1, показывают, что распределенные транзакции оказывают большое влияние на пропускную способность, снижая ее почти в два раза. Поскольку фиксация распределенной транзакции задевает всех ее участников, возрастает и задержка. В этом эксперименте для распределенных транзакций средняя величина задержки примерно в два раза больше, чем у одноузловых транзакций. Например, при наличии пяти серверов задержка одноузловой транзакции составляет 3,5 микросекунды, а распределенной транзакции – 6,7 микросекунд. Мы выполняли аналогичные эксперименты с другими сценариями, включая обновляющие транзакции и транзакции, обращающиеся к большему числу кортежей, и результаты были аналогичными.
Реальные приложения OLTP намного сложнее этого простого эксперимента, потенциально включая: (i) конкуренцию транзакций за одновременный доступ с блокировкой к одним и тем же строкам – как мы увидим в TPC-C подразделе 6.3, (ii) распределенные тупиковые ситуации и (iii) сложные операторы, для выполнения которых требуются данные с нескольких серверов, например, распределенные соединения. Все это еще больше снижает пропускную способность системы при выполнении распределенных транзакций.С другой стороны, при выполнении более дорогостоящих транзакций меньше ощущается влияние распределенности, поскольку большой объем работы, выполняемой локально, затмевает стоимость обработки дополнительных сообщений двухфазной фиксации.
Schism разрабатывается в расчете на приложения OLTP и Web-приложения. Для таких рабочих нагрузок вывод состоит в том, что минимизация числа распределенных транзакций при балансировке нагрузки между узлами способствует значительному повышению транзакционной пропускной способности.
