Примеры систем вывода на основе прецедентов
Вывод по прецедентам – не новая технология, ее возникновение прослеживается в работе Роджера Шанка по динамической памяти [Schank 82]. Изложенные этим исследователем идеи были далее расширены Джанет Колоднер, которая разработала систему CYRUS [Kolodner 83]. С 1988 года проводился ряд ежегодных семинаров под эгидой DARPA (Управление Перспективных Исследований Министерства Обороны США) [Kolodner 88, Hammond 89, Bareiss 91]. Интерес к методу вырос в последние годы, регулярно проводятся конференции и семинары типа широко известного Европейского семинара (EWCBR, в последующем – ECCBR) [Wess 93, Haton 94, Smith 96, Smyth 98, Blanzieri 00, Craw 02, Funk 04], семинара Соединенного Королевства (UKCBR) [UKCBR 04, UKCBR 05].
К ранним разработкам относят CHEF [Hammond 86] – систему, которая предназначалась для формирования кулинарных рецептов. Эта программа принимает информацию о целевых характеристиках блюда (тип, вкусовые качества, своеобразие) и формирует подходящий рецепт. Результатом работы программы должен быть рецепт – последовательность операций, позволяющая приготовить такое блюдо. Получив заказ, программа просматривает свою базу прецедентов, отыскивает в ней рецепт приготовления аналогичного блюда и адаптирует его в соответствии с особенностями текущего заказа.
Из других систем можно отметить PROTOS [Bareiss 88] для классификации и диагностирования нарушений слуха, MEDIATOR [Simpson 85] для области посредничества в спорных судебных вопросах.
При работе над экспертными системами исследователи пришли к выводу, что представление знаний внутри экспертной системы должно со временем привести к созданию систем обучения с помощью компьютера.
В основу программы HYPO [Ashley 88, Ashley 90], которая была создана для обучения студентов-юристов методике ведения судебных дел, положена абстрактная модель процесса прения сторон. И расследования, и рассуждения в юриспруденции направляются аргументацией, а более точно – аргументами, выражающими противоположные интересы, с помощью которых стороны процесса пытаются склонить на свою сторону судью или присяжных, убедить их в том, что именно предлагаемая интерпретация закона и фактов является корректной в данном случае.
Например, дело о разводе может содержать множество пунктов, касающихся раздела имущества, обеспечения детей и т.д., по каждому из которых стороны должны представить свои аргументы.
Что касается доступности коммерческих систем и успеха в информационных приложениях – это система SMART [Acorn 92], которая дала импульс этой технологии. Система SMART предназначена для технической поддержки заказчиков корпорации COMPAQ. Когда заказчик сталкивается с проблемой (например, печать принтера блекнет), подробности передаются в систему. Выполняется начальный поиск в библиотеке прецедентов, чтобы найти случаи с подобными признаками. При недостатке информации система задает дополнительные вопросы. Как только определенный порог достигнут (скажем, прецедент совпадает не менее, чем на 80%), предлагается решение от прецедента. В дополнение к этому, система может быть использована как инструмент обучения.
В дальнейшем COMPAQ расширила эту систему, продвинув ее непосредственно к покупателям. Система QUICKSOURCE [Nguyen 93] позволяет пользователю самому справляться с проблемами и обращаться в центр поддержки в качестве последнего прибежища.
В системе KATE TOOLS компании Acknosoft (Франция) [Althof 95/1] поддерживается упрощенный взгляд на процесс вывода. Входная информация для KATE – это файл, который содержит описания признаков и их значения на специальном языке CASUAL [Althof 95/2]. KATE может работать со сложными данными, представленными в виде структурированных объектов, отношениями или даже общими знаниями о проблемной области. Но для выявления сходства между прецедентами используется одна простая метрика.
Основной акцент делается на отбор прецедентов с помощью алгоритма "ближайшего соседа". KATE использует версию алгоритма ближайшего соседа для вычисления метрики подобия. Близость между двумя случаями x и y, имеющими p признаков вычисляется по формуле:
Similarity(x,y)= -

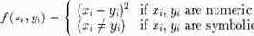
Алгоритм работы системы может быть описан следующим образом:
Classified Data = 0 for each Case x in Casebase do
1. for each y in Classified Data do
Sim(y) = Similarity(y,x)
2. y_max = (y_1,...,y_k) such that
Sim(y_k)= max(K-nearest neighbors)
3. if class(y_max) = class(x)
then classification is correct
Classified Data = Classified Data + {x}
else classification is incorrect
Система KATE не предлагает возможностей для автоматической адаптации решения. Проверка корректности решения невозможна, но есть проверка базы прецедентов на наличие контрпримеров. Все же, KATE – это эффективная индустриальная система, которая позволяет использовать взвешенные признаки при вычислении метрики подобия, а также использовать определяемую пользователем метрику. Ее легко расширять, потому что все функции KATE доступны при подключении сопутствующих динамических библиотек (.dll).
В настоящее время на рынке программных продуктов реально предлагается лишь несколько коммерческих продуктов, реализующих технологию вывода, основанного на прецедентах. Это объясняется, в первую очередь, сложностью алгоритмов и их эффективной программной реализации. Наиболее успешные и известные из присутствующих на рынке продуктов – CBR Express и Case Point (Inference Corp.), Apriori (Answer Systems), DP Umbrella (VYCOR Corp.) [Althof 96].
CBR Express и CasePoint – продукты, предназначенные для разработки экспертных систем, основанных на прецедентах. CBR Express тоже накапливает "опыт", обеспечивая ввод, сопровождение и динамическое добавление прецедентов, а также простой доступ к ним с помощью вопросов и ответов. Обе системы используются при автоматизации информационно-справочных служб и "горячих линий", а также при создании интеллектуальных программных продуктов, систем доступа к информации, систем публикации знаний и т. д.
При общении с системой сначала вводится простой запрос, например: "Мой компьютер не работает". Далее происходит выделение ключевых слов, поиск в базе прецедентов, и генерируется перечень потенциальных решений. Пользователю могут быть также заданы уточняющие вопросы.Предлагаемые варианты решения проблемы могут включать в себя видео- или фотоматериалы. Технология вывода по прецедентам представляет собой основу для практически безграничных приложений, которые наращиваются за счет постоянного сбора информации (причем обеспечивается совмещение структурированных и неструктурированных данных, включая мультимедиа). По мнению компаний, активно использующих эту технологию, таких как Nippon Steel, Lockheed и некоторых других, создается самообучающаяся коллективная память, исключительно удобная для накопления и передачи профессионального опыта.
